Success!
3/3/22
Welcome back to the Odyssey! After 70 hours, my program was able scrape all of the tweets related to Covid and vaccinations in Germany.
Testing the Waters
I mentioned in one of my earlier posts, that I had a few concerns about the tweets I would be scraping. Namely, how well the German language parameter can filter tweets from people who culturally identify as German, how long the scraping would take, and how much space I would need to store the data. Before I started the actual scrape, I checked to see whether these concerns would become issues by analyzing a scrape from a random month. I took a random sample of 100 tweets from the scrape and found that only 6 tweets were from users outside Germany and only 7 tweets were not directly related to Covid.
In KhudaBukhsh’s paper, approximatly 30% of his data was not related to the topic he was analyzing, meaning that the noise in my data was well within the margin of error. Additionally, the scrape only took a bit over two hours and only needed 114 megabytes for storage. Assuming that the number of tweets present in this month (June 2020) was roughly equal to the number of tweets in other months, I estimated that the scraping would only take about 2 days, at most 3, and only about 3 gigabytes of storage would be needed. I decided that both the duration and storage would not be a problem.
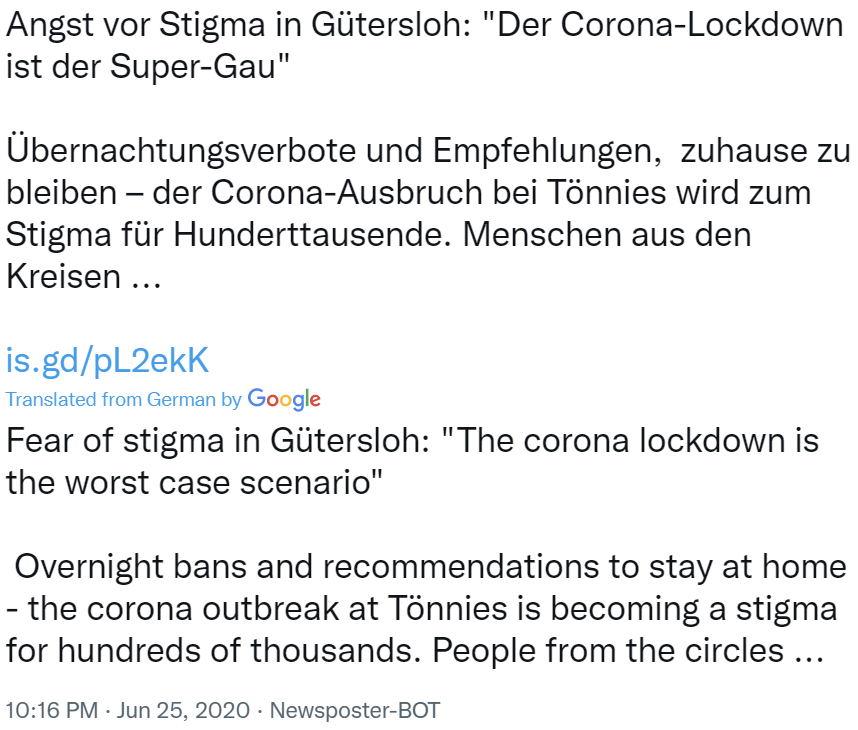


Verification for the test scrape
The Scrape
The actual scrape took 70 hours to complete and a total of 4.1 gigabytes to store, a bit over my initial estimate.
The Code

As you can see, the code to scrape the tweets isn’t that complicated. I have a string variable that holds the base query that is used to search, as well as two lists that hold the date part of the search query and the file name for each scrape, which changes for every month.
twitter_query_no_dates: This is the base query. It ensures that every tweet pulled has at least one of the keywords (which are seperated by an OR) and has been written in German.
dates: I iterate through this list in my code and add it to the end of twitter_query_no_dates so that the query only searches in the month specified.. This allows me to save my data in multiple more organized files rather than one massive file. (You can only see the last 7 months here).
file_names: This list holds the names for each file that will be saved
The loop: This loop consists of an inner and outer loop. The outer loop iterates through each month and creates a list to store all of the tweets for that month. For each iteration of the outer loop, the inner loop iterates through every tweet matching the corresponding query using snscrape’s TwitterSearchScraper method. Once the inner loop finishes, I convert the list into a pandas.Dataframe object and save it as a CSV file. You can also save the Dataframe as a json file, which is computationally more efficient, but CSV files are more human friendlym which is why I opted to use them.
The Data
Visualization of the dataset: This image is from the raw March 2020 dataset. I have removed personal identifying information because of privacy concerns.
My program scraped a total of 12 million tweets. The distribution for each month wasn’t symetrical, with January 2020 having only 10K tweets and November 2021 having 1.1 million tweets. As I mentioned in an earlier post, I will be using a random subset of tweets to address the variability across months. However, I didn’t expect such an extreme difference in the number of tweets. January and February are the main problem as all other months are in a similar range. In order to address the problem I will have to either merge the data for January and February, or remove them altogether depending on the sample size that I use.
Ethics
All tweet attributes.
I want to talk a bit more about what I actually saved from each tweet, because it touches on some broader ethical concerns regarding scraping. You might have noticed that when I store my list as a Dataframe object, I have a second columns parameter. This parameter allows me to specify what attributes from each tweet I want to save (Tweet ID, Date, Username, UserLocation, Language, Tweet URL, Tweet Text). What’s important to note is that these tweets reflect the opinions of real people and therefore scraping any information that isn’t strictly necessary is highly unethical. Further, as it currently stands, my data set contains identifying information such as the tweet ID, the username of the author, and tweet URL. While I need this information to clean my data, if I were to share this dataset, these personal identifiers could easily be used to target and harass specific users based on their views. Therefore, especially when scraping massive amounts of data like I have done, it is crucial to be aware of the privacy concerns and act accordingly. For example, during my cleaning procedure I will remove everything, including mentions, except for the actual body of the tweet.
Now that I have the tweets, the next step is to process the data. Stay tuned for one of the upcoming posts to see how I clean the tweets.